As much as we would like to believe that technology is logical and follows the rules, deciphering the “Why?” is bewildering at times. This was recently the case when troubleshooting a Remote Desktop Service (RDS) issue for one of our clients.
Background:
Not too long ago, this client was migrated fully from a brick-and-mortar data center to Azure. It was mostly a lift and shift migration with only a few deviations. When the problem was first encountered, they had been 100% production for about a month in their new environment.
Symptoms:
The issue first hit on a weekday morning. All users log in around the same time, so we simultaneously received monitoring alerts and notifications from our client that the RD sessions were extremely slow. We quickly confirmed that a handful of servers were hosting over double their normally expected sessions. We coordinated with onsite IT staff to try and move users to less burdened servers, but were troubled by these two main issues:
1) The round robin DNS load balancing was not working, and
2) The session cap limit set for each session host was also failing.
Troubleshooting:
Incident #1:
The Event Viewer logs (Event viewer - Applications and Services Logs -> Microsoft -> Windows -> TerminalServices-SessionBroker -> Admin) were filled with one specific error – Event ID 802, “Error: Cannot create another system semaphore.”
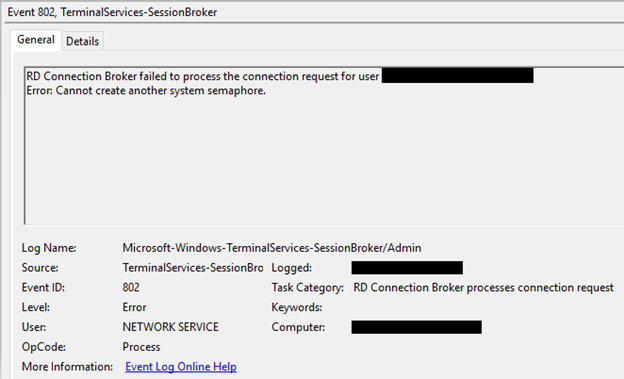
The Operational logs in the same location confirmed that the servers were experiencing a, “…failure to redirect…” as well.
Great, we have the main error! We just need to look it up and apply the fix. No big deal, right? Right?... Not right. This specific “semaphore” Event ID 802 error is just rare enough to barely have any information on it. If you do a search for it, you will probably find these three main links:
[SOLVED] Cannot Create Another System Semaphore Error Problem (techinpost.com)
2016 RDS issue : sysadmin (reddit.com)
The links mention checking your GPOs (we are not using them for the RDS setup), removing the offending session host server from a collection and rejoining it, and rebuilding the collection entirely. The first link relates the semaphore error to SQL (the Windows Internal Database on the session broker server is a SQL database), so we restarted the service and made sure that the recovery settings were to restart upon failure.

Around this time, the errors started to go away... which made our troubleshooting efforts harder. It was hard to determine if what we did fixed the issue or if it was just coincidence. The important part was that the client no longer had the RDS lag. Besides the database service, we adjusted the nightly reboot times and we reported to the client that the issue was resolved and what we thought was the solution.
Incident #2:
About a week later, the same errors started to show up followed by the same load balancing issues. No additional errors or log info to help guide us in the correct direction. It was time for drastic measures, so we uninstalled the Session Broker role from the gateway server (which removes any server collections you have created), re-installed it:
and re-created the session server collection:

After rebuilding the setup, everything worked 100%. Following multiple reboots and testing by multiple users, there were no more semaphore errors. We kept our fingers crossed and hoped that during the morning user log in rush, there would be no issues… but of course there were! Same errors. Same logs. Same symptoms.
Solution:
At this point, we were left to go back to the basics and check over the configuration from top to bottom. Luckily, one of the first few items that we decided to address were the SSL certificates. A wildcard SSL was being used on the gateway server, so, for the sake of uniformity and to rule out any certificate issues, we did a fresh install of that cert on every session host server. After the installation, we ran this Power Shell command to force the servers to use that cert as the Remote Desktop listener certificate:
wmic /namespace:\\root\cimv2\TerminalServices PATH Win32_TSGeneralSetting Set SSLCertificateSHA1Hash="<thumbprint of cert>"

Remote Desktop listener certificate configurations - Windows Server | Microsoft Docs
This is what finally solved our issues.
We have not seen the, “Cannot create another system semaphore,” error since the fix and hopefully never will again! Troubleshooting this issue was an adventure, but I hope this blog post can be a cheat code for anyone else facing this issue. Good luck!